
Inside Kenaz Loader
Kenaz Loader perform the task of loading previously compiled Kenaz code and making them available to the C++ code.
Loading
The loading is quite straight forward. When previously saving, we have annotated the code with various information, as shown in the following diagram :

At load-time, those references are tracked and replaced with their real value. References to functions are replaced by functions's address, enum value by their integer value... At the end of this reference replacing process, we have a fully functional opcode flow that can now be called.
From C++ to Kenaz
There are two ways to call Kenaz code from C++ : using the reflection API, or
using the "Full Integration" feature of kenaz. The reflection API looks like C# or Java reflection API, and from a technical point of view,
there is nothing really interesting, except maybe the code to call function. This is the only part in Kenaz that had to be written in assembly. The code had
to mimic a function call with stdcall/thiscall calling convention (thus, we can't use function with variable argument because they use cdecl calling convention). The assembly code pushes arguments on the stack, move
the Kenaz "this pointer" to ecx and finally calls the function and returns immediately. By returning immediately, we let the FPU stack and ALU reg in
their current state, meaning that the caller will find what it expects where it should be. In the following code, val is the argument list. It was previously
built by another function from the kenaz API, the code you see here is a private function)
template <typename T> T KzMethod::doInvoke(unsigned int *val, int num) { void * func = this->m_ptr; void * thisPtr = this->m_thisPtr; _asm { mov eax, val; mov ecx, num; //Push argument on stack pushLoop: cmp ecx, 0; je doCall; dec ecx; push DWORD PTR[eax + 4*ecx]; jmp pushLoop; doCall: mov eax, func; mov ecx, thisPtr; call eax; //Here, we let register / FPU stack in their current state } }
The second way to call Kenaz code from C++ code is to use the full integration feature of Kenaz. By using the apiOutput metadata, we tell the kenaz compiler to generate a C++ stub of the Kenaz class/interface. For example, the kenaz class :
class truc [apiOutput()] { public int a; public int c; public int bidule() { return this.a; } }
namespace KzAPI { #pragma pack(1) class KZtruc { public: virtual int bidule()=0; int a; int c; }; #pragma pack() };
- We don't want user to instanciante kenaz object with the C++ new operator
- Without the virtual keyword, the C++ compiler will attempt and fail to perform a static linking
- With the virtual keyword, the C++ compiler will expect a V-table to be present and perform call to the function through v-table, and this is a great thing for us (explication comes right now)
- Member variables are not reordered (but the msdn informs us that they are packed on 8 bytes boundaries, while kenaz packs them contiguously (hence the pragma pack directive)
- If there are n base object, there will be n virtual tables, stored at the beginning of the object, in the order of base class declaration. Functions are stored in the virtual table in the order of declaration.
- Pointer(s) to virtual function from the object are stored in the first v-table, after the function pointer from the first base class (if any)

Another example, lets take the following C++ code :
class a { public: virtual int func1()=0; } class b { public: virtual int func2()=0; } #pragma pack(1) class myClass : public a, public b { public: virtual int bidule()=0; int a; int c; }; #pragma pack()

Now that we have theses informations, we are able to construct objects the way vc++ does, and that is what the Kenaz loader also does. It generates v-table in the order expected by vs, and places member where vs would place them. That means, using the stub generated by Kenaz, we are able to call Kenaz code directly from C++ code without any overhead. (just an indirect call).
From Kenaz to C++
Calling C++ code from kenaz is easy. In kenaz, this is done the following way :
class myClass { external int func(); int test() { return func(); } }
Then, the kenaz compiler makes no difference between an external call or a standard kenaz function call. (except for the calling convention, which can be specified using the convention metadata). The question left is "how to make the binding between kenaz code and C++ code". When the CPU will execute the code to call "func", it will first be redirected to a temporary code, and this is this temporary code that will redirect the code flow to the real target, specified by the C++ user (if no target is provided, it resolves by default to a function that throws an exception). To make things a little bit easier to understand :
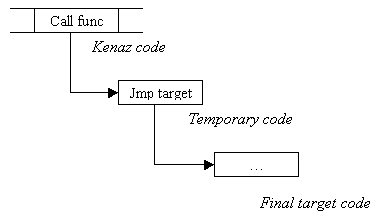
You see here the indirection. The benefit of this method is that we are able to modify the target at run time without having to modify existing kenaz code, just by modifying the temporary code. The temporary code performs a jmp instead of a call to leave the stack intact (call push EIP on the stack).
top of page